
 康维主机测评-网站SEO优化
康维主机测评-网站SEO优化
关于百度搜索引擎工作原理知识,有不少站长SEO还没有认真阅读和理解,本文解读百度蜘蛛抓取系统与建库索引,让SEOer对百度蜘蛛的收录索引建库有更多了解。

一,搜索引擎蜘蛛抓取系统的基本框架
互联网信息爆发式增长,如何有效的获取并利用这些信息是搜索引擎工作中的首要环节。数据抓取系统作为整个搜索系统中的上游,主要负责互联网信息的搜集、保存、更新环节,它像蜘蛛一样在网络间爬来爬去,因此通常会被叫做 “spider”。例如我们常用的几家通用搜索引擎蜘蛛被称为:Baiduspdier、Googlebot、Sogou Web Spider 等。
蜘蛛抓取系统是搜索引擎数据来源的重要保证,如果把 web 理解为一个有向图,那么 spider 的工作过程可以认为是对这个有向图的遍历。从一些重要的种子 URL 开始,通过页面上的超链接关系,不断的发现新 URL 并抓取,尽最大可能抓取到更多的有价值网页。对于类似百度这样的大型 spider系统,因为每时每刻都存在网页被修改、删除或出现新的超链接的可能,因此,还要对 spider 过去抓取过的页面保持更新,维护一个URL库和页面库。
下图为蜘蛛抓取系统的基本框架图,其中包括链接存储系统、链接选取系统、dns 解析服务系统、抓取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。Baiduspider即是通过这种系统的通力合作完成对互联网页面的抓取工作。
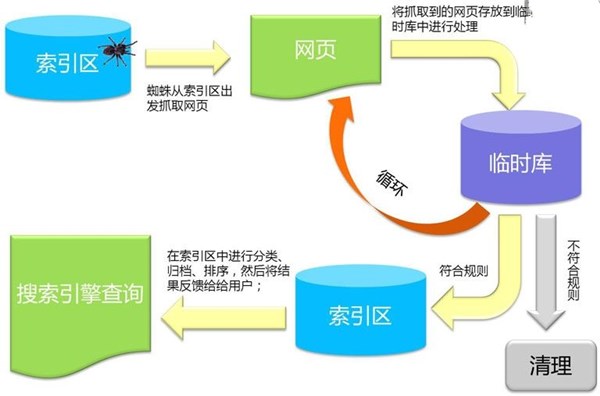
二,百度蜘蛛主要抓取策略类型
上图看似简单,但其实百度蜘蛛在抓取过程中面对的是一个超级复杂的网络环境,为了使系统可以抓取到尽可能多的有价值资源并保持系统及实际环境中页面的一致性同时不给网站体验造成压力,会设计多种复杂的抓取策略。以下做简单介绍:
1. 抓取友好性
互联网资源庞大的数量级,这就要求抓取系统尽可能的高效利用带宽,在有限的硬件和带宽资源下尽可能多的抓取到有价值资源。这就造成了另一个问题,耗费被抓网站的带宽造成访问压力,如果程度过大将直接影响被抓网站的正常用户访问行为。因此,在抓取过程中就要进行一定的抓取压力控制,达到既不影响网站的正常用户访问又能尽量多的抓取到有价值资源的目的。
通常情况下,最基本的是基于 ip 的压力控制。这是因为如果基于域名,可能存在一个域名对多个 ip(很多大网站)或多个域名对应同一个 ip(小网站共享 ip)的问题。实际中,往往根据 ip 及域名的多种条件进行压力调配控制。同时,站长平台也推出了压力反馈工具,站长可以人工调配对自己网站的抓取压力,这时百度 spider 将优先按照站长的要求进行抓取压力控制。
对同一个站点的抓取速度控制一般分为两类:
其一,一段时间内的抓取频率;
其二,一段时间内的抓取流量。同一站点不同的时间抓取速度也会不同。
例如夜深人静月黑风高时候抓取的可能就会快一些,也视具体站点类型而定,主要思想是错开正常用户访问高峰,不断的调整。对于不同站点,也需要不同的抓取速度。
三,新链接重要程度判断
在建库环节前,百度蜘蛛会对页面进行初步内容分析和链接分析,通过内容分析决定该网页是否需要建索引库,通过链接分析发现更多网页,再对更多网页进行抓取——分析——是否建库 & 发现新链接的流程。理论上,百度蜘蛛会将新页面上所有能 “看到” 的链接都抓取回来,那么面对众多新链接,
百度蜘蛛根据什么判断哪个更重要呢?
两方面:
1,对用户的价值
-
内容独特,百度搜索引擎喜欢原创唯一的内容
-
主体突出,切不要出现网页主体内容不突出而被搜索引擎误判为空短页面不抓取
-
内容丰富
-
广告适当
2,链接重要程度
-
目录层级——浅层优先
-
链接在站内的受欢迎程度

四,百度优先建重要库的原则
百度蜘蛛抓了多少页面并不是最重要的,重要的是有多少页面被建索引库,即我们常说的 “建库”。众所周知,搜索引擎的索引库是分层级的,优质的网页会被分配到重要索引库,普通网页会待在普通库,再差一些的网页会被分配到低级库去当补充材料。目前 60% 的检索需求只调用重要索引库即可满足,这也就解释了为什么有些网站的收录量超高流量却一直不理想。
那么,哪些网页可以进入优质索引库呢。其实总的原则就是一个:对用户的价值。包括却不仅于:
-
有时效性且有价值的页面:在这里,时效性和价值是并列关系,缺一不可。有些站点为了产生时效性内容页面做了大量采集工作,产生了一堆无价值面页,也是百度不愿看到的 .
-
内容优质的专题页面:专题页面的内容不一定完全是原创的,即可以很好地把各方内容整合在一起,或者增加一些新鲜的内容,比如观点和评论,给用户更丰富全面的内容。
-
高价值原创内容页面:百度把原创定义为花费一定成本、大量经验积累提取后形成的文章。千万不要再问我们伪原创是不是原创。
-
重要个人页面:这里仅举一个例子,科比在新浪微博开户了,即使他不经常更新,但对于百度来说,它仍然是一个极重要的页面。
五,哪些网页无法建入索引库
上述优质网页进了索引库,那其实互联网上大部分网站根本没有被百度收录。并非是百度没有发现他们,而是在建库前的筛选环节被过滤掉了。
那怎样的网页在最初环节就被过滤掉了呢:
-
重复内容的网页:互联网上已有的内容,百度必然没有必要再收录。
-
主体内容空短的网页
-
有些内容使用了百度蜘蛛无法解析的技术,如 JS、AJAX 等,虽然用户访问能看到丰富的内容,依然会被搜索引擎抛弃
-
加载速度过慢的网页,也有可能被当作空短页面处理,注意广告加载时间算在网页整体加载时间内。
-
很多主体不突出的网页即使被抓取回来也会在这个环节被抛弃。
-
部分作弊网页
更多关于百度蜘蛛抓取系统原理与索引建库,请前往百度站长论坛查看文档。







